데이터셋 불러오기
import os
import urllib.request
TITANIC_PATH = os.path.join("datasets", "titanic")
DOWNLOAD_URL = "https://raw.githubusercontent.com/rickiepark/handson-ml2/master/datasets/titanic/"
def fetch_titanic_data(url=DOWNLOAD_URL, path=TITANIC_PATH):
if not os.path.isdir(path): # 우선 디렉터리가 있는지 확인
os.makedirs(path) # 디렉터리가 없으므로 생성
for filename in ("train.csv", "test.csv"):
filepath = os.path.join(path, filename) # 디렉터리 경로와 파일명을 합치고
if not os.path.isfile(filepath): # 디렉터리에 파일이 존재하는지 확인
print("Downloading", filename)
urllib.request.urlretrieve(url + filename, filepath) # 파일이 없으므로 urlretrieve를 이용해 파일 다운로드
fetch_titanic_data()os, urllib 라이브러리를 이용해 핸즈온 머신러닝 2판의 번역자(박해선 님) 에게서 타이타닉 데이터셋을 불러온다.
fetch_titanic_data 함수를 만들어서 디렉터리에 파일이 없을 시 웹에서 다운로드한다. 당연히 데이터셋을 받은 적 없으므로 Downloading 문구가 뜨게 된다.
os.makedirs(path) : 디렉터리가 없을 시 path에 새로 생성한다.
os.path.join(path, filename) : 경로를 이어붙여줌.
urllib.request.urlretrieve(url + filename, filepath) : 경로의 웹에 있는 자료 다운로드
import pandas as pd
def load_titanic_data(filename, titanic_path=TITANIC_PATH):
csv_path = os.path.join(titanic_path, filename)
return pd.read_csv(csv_path) #판다스 데이터프레임을 통해 csv 파일 불러오는 함수train_data = load_titanic_data("train.csv")
test_data = load_titanic_data("test.csv") # 각각 불러와준다train_data.head()
train_data = train_data.set_index("PassengerId")
test_data = test_data.set_index("PassengerId")set_index() : index로 삼기를 원하는 칼럼 이름을 넣어준다.
우리는 승객 번호/생존여부 의 형태로 출력을 만들것이기 때문에 PassengerId 로 설정해준다.
train_data.info()
train_data[train_data["Sex"]=="female"]["Age"].median()train_data 에서 성별이 여성인 승객의 나이의 중간값은 27이 나온다.
train_data.describe()
train_data["Pclass"].value_counts()value_counts()는 해당 열의 특정 값들의 개수를 알려준다.

train_data["Survived"].value_counts()
train_data["Sex"].value_counts()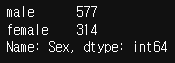
train_data["Embarked"].value_counts()
여러 칼럼들의 값들을 알아보았다.
전처리
다음으로 할 것은 훈련 데이터를 불러왔으므로 전처리를 통해 알고리즘이 학습하기 쉬운 데이터 형태로 가공하는 것이다.
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler())
])SimpleImputer는 칼럼 중 비어있는 값에 어떤 값을임의로 채워줄지 결정한다. 여기서는 "median"을 통해서 null 값은 각 열의 중간값으로 채우도록 했다.
StandardScaler는 데이터의 표준화를 담당한다. imputer를 통해 null 값들을 전부 처리해 주었으니 간단히 표준화를 할 수 있게 되었다. 평균이 0이고 분산이 1이 되도록 범위를 바꾸어 주었기 때문에, 단순히 큰 값이 학습에 큰 영향을 주는 것을 피할 수 있다. 대~~부분의 상황에서는 정규화&표준화가 권장된다. (어찌보면 당연하다)
이 두 절차를 파이프라인으로 묶어서 num_pipeline 변수에 할당한다. 이 파이프라인은 단순히 실수를 처리하기 때문에 실수 값이 아닌 열들의 null 값을 대치하기 위해서는 다른 파이프라인을 사용할 것이다.

from sklearn.preprocessing import OneHotEncoder
cat_pipeline = Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("cat_encoder", OneHotEncoder(sparse=False)),
])
원-핫 인코딩을 통해서 실수 값이 아닌 열을 처리해준다.
여기서는 imputer의 전략을 "most_frequent" 로 설정해 그 열의 가장 두드러지게 나타나는 특성을 빈 값에 그대로 적용하도록 했다.
자꾸 까먹게 되는데, OneHotEncoder 에서 sparse = True 는 행렬을 반환하고, sparse = False 는 배열을 반환한다. 우리는 당연히 배열이 필요하므로 False 로 설정한다.
이 파이프라인을 cat_pipeline 이라는 이름으로 선언한다. (cat - 카테고리)
원-핫 인코딩이란?
- 원하는 한 개의 요소만 1로 만들고 나머지 요소는 0으로 만들어 컴퓨터가 구분할 수 있게 해주는 것.
-타이타닉 데이터의 Embarked, 성별 칼럼은 값이 실수 값으로 들어 있는 것 대신 male, female / S,C,Q 으로 들어가 있다. 이를 처리하기 위해서는 0과 1로 원하는 값이 들어있는 인덱스를 변환해준다.
ex)
S C Q
0 1 0
0 0 1
1 0 0
0 0 1
0 1 0
이렇게 변환하면 컴퓨터가 이해할 수 없는 문자열 대신 정수 값으로 구분하게 만들어줄 수 있다.
from sklearn.compose import ColumnTransformer
num_attribs = ["Age", "SibSp", "Parch", "Fare"]
cat_attribs = ["Pclass", "Sex", "Embarked"]
preprocess_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs), # ("파이프라인 이름", 파이프라인 이름, 칼럼 값)
])
숫자 값과 카테고리(문자열 변수) 를 전처리할 파이프라인 두개를 만들었다. 한번에 적용하기 위해서 ColumnTransformer 를 이용해서 이어붙인다음 적용해줄 계획이다.
리스트 두개를 선언해서, 각각 처리하고 싶은 칼럼의 이름을 넣어준다.
num_attribs에는 "Age", "SibSp", "Parch", "Fare" 로 실수 값을 가진 열들이 들어갔고,
cat_attrtibs에는 "Pclass", "Sex", "Embarked" 로 문자열 값을 가진 열들이 들어갔다.
이것들을 preprocess_pipeline 이란 이름으로 한번에 엮어서 선언한다.
변환 후 알고리즘 적용
파이프라인을 만들었으니 훈련 데이터에 적용한 후 훈련시키면 된다.
X_train = preprocess_pipeline.fit_transform(train_data[num_attribs + cat_attribs])
X_train
fit_transform을 통해 학습(평균, 분산 구함) 한 후 변환해 준다.
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
forest_clf.fit(X_train, y_train)랜덤 포레스트를 통해 예측을 해 보자.
X_test = preprocess_pipeline.transform(test_data[num_attribs + cat_attribs])
y_pred = forest_clf.predict(X_test)당연하게도 여기서 테스트 세트에서는 fit을 하면 안된다. 그러면 훈련 세트 + 테스트 세트의 값들에서 평균 및 분산을 구할것이기 때문에.
이 상태에서 바로 캐글에 업로드 해 얼마나 좋은 예측을 했는지 평가받을 수 있다. 하지만 먼저 스스로 평가해보는 것이 좋다.
예측 완료 후
from sklearn.model_selection import cross_val_score
forest_scores = cross_val_score(forest_clf, X_train, y_train, cv=10)
forest_scores.mean()
예측을 한 후 교차 검증을 통해 약 0.809의 정확도를 얻은 것을 확인할 수 있다. \
from sklearn.svm import SVC
svm_clf = SVC(gamma="auto")
svm_scores = cross_val_score(svm_clf, X_train, y_train, cv=10)
svm_clf.fit(X_train, y_train)
svm_scores.mean()서포트 벡터 머신을 통해서도 예측을 해보면 0.8249로 랜덤 포레스트보다 더 높은 점수가 나온다.
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.plot([1]*10, svm_scores, ".")
plt.plot([2]*10, forest_scores, ".")
plt.boxplot([svm_scores, forest_scores], labels=("SVM","Random Forest"))
plt.ylabel("Accuracy", fontsize=14)
plt.show()
matplotlib을 이용해서 랜덤 포레스트와 서포트 벡터 머신의 정확도 분포를 시각화해보면, 랜덤 포레스트는 정확도가 0.74~0.88 까지 넓게 분포하고 있고, 서포트 벡터 머신은 0.77~0.88 까지 분포하고 있다. 따라서 일반화는 서포트 벡터 머신이 더 잘하는 것으로 보여지기 때문에 SVM 을 사용하도록 하자.
핸즈온 머신러닝의 박해선 저자님의 말씀
이 결과를 더 향상시키려면:
- 교차 검증과 그리드 탐색을 사용하여 더 많은 모델을 비교하고 하이퍼파라미터를 튜닝하세요.
- 특성 공학을 더 시도해 보세요, 예를 들면:
- 수치 특성을 범주형 특성으로 바꾸어 보세요: 예를 들어, 나이대가 다른 경우 다른 생존 비율을 가질 수 있습니다(아래 참조). 그러므로 나이 구간을 범주로 만들어 나이 대신 사용하는 것이 도움이 될 수 있스니다. 비슷하게 생존자의 30%가 혼자 여행하는 사람이기 때문에 이들을 위한 특별한 범주를 만드는 것이 도움이 될 수 있습니다(아래 참조).
- SibSp와 Parch을 이 두 특성의 합으로 바꿉니다.
- Survived 특성과 관련된 이름을 구별해 보세요.
- Cabin 열을 사용하세요. 예를 들어 첫 글자를 범주형 속성처럼 다룰 수 있습니다.
train_data["AgeBucket"] = train_data["Age"] // 15 * 15
train_data[["AgeBucket", "Survived"]].groupby(['AgeBucket']).mean()나이대별로 훈련 데이터를 나누어서 평균을 낸 결과를 확인해 보자.

~15살까지의 생존자 비율이 가장 많고, 그 다음은 30살~45살 이었다.
나이대 별로 생존자 비율을 따져볼 수 있다.
train_data["RelativesOnboard"] = train_data["SibSp"] + train_data["Parch"]
train_data[["RelativesOnboard", "Survived"]].groupby(['RelativesOnboard']).mean()
마찬가지로 타이타닉에 탑승한 인원 중 특정인의 친인척수에 따른 생존 비율 또한 볼 수 있다.
#안녕하세요. 박해선입니다.
#승객번호는 test_data 데이터프레임의 인덱스로 사용되고 있으므로 다음처럼 하나의 넘파이 배열을 만든다음 c
#sv 파일로 저장할 수 있습니다.
pd.DataFrame({'PassengerId':test_data.index, 'Survived':y_pred}).to_csv('submission.csv', index=None)
#정확한 csv 포맷은 캐글 대회의 안내 사항을 참고하세요.
#감사합니다.
마지막으로 캐글의 제출 양식에 맞추어 제출하면 된다.
'프로그래밍 공부 > 핸즈온 머신러닝 2판' 카테고리의 다른 글
| [핸즈온 머신러닝 2판] 3장 분류 연습문제 2번 (0) | 2022.10.30 |
|---|---|
| [핸즈온 머신러닝 2판] 3장 연습문제 1번 (0) | 2022.10.29 |
| [핸즈온 머신러닝 2판] 책의 결과와 실제 실습 결과가 다른 이유 (0) | 2022.10.23 |
| [핸즈온 머신러닝 2판] 3장 분류 / 정밀도와 재현율 (0) | 2022.10.23 |
| [핸즈온 머신러닝 2판] 2.7 모델 세부 튜닝 (0) | 2022.10.21 |