객체 지향 프로그래밍의 특징
객체 지향 프로그래밍이란?
- 프로그램 설계 시 프로그램을 수많은 객체로 나누고 이 객체들의 상호작용으로 서술하는 방법.
객체지향의 장점
- 코드 재사용이 용이함. 클래스를 기능별로 분할하였기에 모듈화도 용이하고 상속을 통해 높은 확장성을 가질 수 있다. 객체를 만들어두면 재사용할 수 있다. 그렇기 때문에 유지보수성 또한 뛰어나다. (게임은 늘 갈아엎고 뒤집히는 경우가 많기 때문에 유지보수성에 특히 민감하다)
객체지향의 특징
캡슐화(encapsulation)
- 클래스를 통해 변수와 함수를 하나의 단위로 묶는다.
하나의 기능을 하는 요소들을 모두 한 캡슐에 모아둔 것 같다고 하여 캡슐화이다.
같은 역할을 하는 변수, 함수들을 모아두었기 때문에 의존성, 커플링이 줄어든다. 그로 인해 관리가 용이해진다.
정보은닉(Information hiding)
-프로그램의 세부 구현을 감추는 것.
private 접근자를 통해 변수와 객체를 감추고, public 접근자로 선언된 메소드(함수) 로만 접근을 허용하여 접근을 제한하는 것.
왜? 의도하지 않은 접근을 제한하기 위하여 (= 설계한 클래스를 다른 사람이, 혹은 본인이 잘못 쓰는 것을 방지하기 위하여.)
ex) 다른 사람이 설계한 클래스의 변수에 직접 접근하여 값을 바꾸는 것을 막는다.
이러면 코드 사용자는 프로그램의 내부 구현에 신경 쓸 필요 없이 메소드를 통해 원하는 기능을 호출하기만 하면 된다.
제대로 쓰기엔 쉽게 설계하고, 잘못 쓰기엔 어렵게 설계하라.
또한, 객체들 끼리 서로의 구현과 상태를 상관하지 않고 단지 사용하게만 함으로써 의존성을 낮추는 역할을 한다.
상속(Inheritance)
- 자식 클래스가 부모 클래스의 변수, 함수를 물려받는 것.
자식 클래스는 자신만의 특성을 오버라이딩을 통해 디테일하게 구현한다.
왜? 다형성과도 연관되는 질문인데, 부모와 자식을 다형성으로 엮어놓으면 부모에서 추상적인 형태를 주고, 자식에서 세밀화하여 유연하게 코드를 작성할 수 있으며 생산성, 유지보수성 또한 올라간다. (유지보수성의 경우 무분별한 복사-붙여넣기를 막을 수 있는 효과가 있다.)
(복붙으로도 간단하게 상속으로 할 수 있는 일을 할 수 있잖아? 라는 후질문이 들어오면 ) -> 또한 나중에 기능 개선 시 ‘교체’가 가능하단 장점이 있다. ex) A사의 타이어 객체를 사용하고 있다가, B사의 타이어 객체로 개선하고 싶으면 B사는 ‘타이어’를 부모로 상속받아 자신에 맞게 구현하기만 하면 된다.
카피-페이스트로 만들어진 코드들은 각각이 다른 코드이므로 개선이 필요할 때 구현을 따로따로 해줘야 하며, 유지보수가 어려워진다.
추상화(abstraction)
-공통의 속성이나 기능을 묶어 이름을 붙이는 것
C++ 언어 특징
C++ 언어의 주요 설계 목표
- C언어와의 호환성(Compatibility) : 기존에 작성된 C 프로그램을 그대로 사용할 수 있도록 C언어의 문법적 체계를 그대로 계승하였다. 또한, C 언어로 작성되어 컴파일된 목적 파일(object file)이나 라이브러리를 C++ 프로그램에서 링크하여 사용할 수 있도록 하였다.
- 객체 지향 : 소프트웨어의 재사용을 통해 생산성을 높일 수 있도록 객체 지향 개념을 도입하였다.
- 타입 체크 : 타입 체크를 엄격히 하여 실행 시간 오류의 가능성을 줄이고 디버깅을 돕는다.
- 효율성 저하 최소화 : 멤버 함수에 인라인 함수를 도입하는 등 함수 호출로 인한 시간 저하를 막는다.
(인라인 함수란? 컴파일러에게 해당 함수를 호출할 떄 함수 호출 대신 함수의 코드 자체를 삽입하도록 요청하는 함수. 함수 호출에 따른 오버헤드를 줄이고 성능 향상에 도움이 된다.)
C 언어 -> C++ 로 오면서 추가한 기능
- 함수 오버로딩(function overloading) : 매개 변수의 개수나 타입이 다른 동일한 이름의 함수들을 선언할 수 있게 한다.
- 디폴트 매개 변수(default parameter) : 매개 변수에 값이 전달되지 않은 경우 디폴트 값이 전달되도록 함수를 선언할 수 있게 한다.
- 인라인 함수(inline function) : inline 키워드를 사용하여 함수 호출 대신 함수 코드를 삽입하는 방식으로 변경할 수 있으며 실행 시간을 줄여 줄 수 있다.
- 참조(reference) : 변수에 별명을 붙여 변수 공간을 같이 사용할 수 있는 참조의 개념을 도입하였다.
참조에 의한 호출(call by reference) : 함수 호출 시 참조를 전달할 수 있게 한다.
- new와 delete 연산자 : 동적 메모리 할당 / 해제를 위한 new, delete 연산자를 도입하였다.
- 연산자 재정의(operator overloading) : 기존의 연산자에 새로운 정의를 더할 수 있다.
- 재네릭(generics) : 함수나 클래스를 데이터 타입에 의존하지 않고 일반화시킬 수 있다.
C++의 특성
흔히 말하는 객체 지향 언어의 특징들을 갖고 있다. 그러나 객체 지향 언어와 다르게 클래스나 객체를 생성하지 않고도 컴파일될 수 있다.
- 프로그래밍 모델 : 절차 지향 프로그래밍과 객체 지향 프로그래밍 모두를 지원한다. (멀티 패러다임)
플랫폼 종속성 : C++은 플랫폼에 종속적이다. (코드의 실행 결과난 동작이 운영체제, 하드웨어, 컴파일러 에 따라 달라 질 수 있다.)
- 주요 특징 : 연산자 오버로딩, Goto Statement, 구조체, 포인터, 유니온(하나의 메모리 공간을 공유하는 여러 멤버를 정의할 수 있는 사용자 정의 데이터 타입. 모든 멤버가 동일한 메모리 공간을 공유한다.) 등을 지원한다.
컴파일과 인터프리션 : 컴파일만 가능, 인터프리트는 불가
라이브러리, 코드 재사용성 : C++은 제한적인 라이브러리와 저 레벨 함수 기능들을 가진다. 또한 기본적인 시스템 라이브러리(POSIX, Windows API) 에 대한 직접 호출을 허용한다.
- 메모리 관리 : C++은 메모리 관리를 수동으로 하게 된다.
- 전역 범위 : C++은 전역, 네임스페이스 범위를 지원한다.
- 접근 관리와 객체 보호 : 지속해서 보호되는 유연한 모델이 가능하다.
C++의 주요 기능
- 동적 및 정적 메모리 할당 : C++에서는 동적, 정적 할당이 모두 가능하다. 이는 사용자가 컴파일 시간과 실행 시간에 변수 객체 등에 메모리를 할당할 수 있게 한다.
- 템플릿 생성 : 제네릭을 이용하여 제네릭 함수, 클래스 등을 만들고, 이는 여러 가지 데이터 타입에 대해 특정 기능을 지원하게 할 수 있다.
- 연산자 오버로딩 : 사용자로 하여금 특정 연산자들이 원래 사용되던 기능이 아닌 문맥과 상황에 맞게 변형되어 사용할 수 있다.
절차 지향 프로그래밍 VS 객체 지향 프로그래밍
절차 지향 프로그래밍(Procedural Programming)
절차 지향 프로그래밍이란 실행하고자 하는 절차대로 일련의 명령어를 나열하여 프로그래밍하는 방법이다.
작업을 절차로 표현하며, 명령의 순서나 흐름에 중점을 둔다.
흐름도를 설계하여 흐름도상 동작을 함수로 작성 후, 흐름도에 따라 일련의 동작들이 흐름에 맞추어 실행되도록 구현한다.
객체 지향 프로그래밍(Object-Oriented Programming)
객체 지향 프로그래밍은 물체 간의 관계, 상호 작용 등으로 복잡하게 구성된 실제 세계와 가깝게 모델링(modeling)하여 프로그래밍하는 방법이다.
실제 세계의 물체를 객체로 표현하고, 객체들의 관계와 상호 작용을 객체 지향 기법으로 구현한다.
컴파일과 링킹
컴파일(Compile)
- C++ 컴파일러를 이용하여 소스 프로그램을 컴파일하게 되면, C++ 컴파일러는 프로그램이 문법에 맞게 작성되었는지 검사 후, 기계어로 변환하여 목적 파일(object file)을 생성한다.
목적 파일에는 C++ 프로그램에 있는 함수, 객체, 데이터 등의 참조 표시만 있을 뿐 코드를 포함하지 않는다.
따라서 이들과 결합하기 위해 링킹 과정을 거쳐야 한다.
링킹(Linking)
- 링킹이란 어떤 목적 파일이 참조하는 C++ 표준 라이브러리나 다른 목적 파일 속에 있는 함수, 객체, 데이터를 포함하여 실행에 필요한 기계어 코드를 확보해 하나의 실행파일(exe)로 만드는 과정이다.
실행 파일에는 실행에 필요한 모든 요소가 들어있다. 만약, 링킹 과정 동안 목적 파일에서 참조하는 코드를 발견하지 못하면 링크 오류가 발생한다.
전체적인 C++ 컴파일 과정
전처리 단계 : 전처리기 매크로들을 처리(#include, #define 등)
1) 문자 해석하기
2) '\' 문자 해석하기
3) 전처리 토큰들로 분리
소스 파일을 주석 -> 공백 문자 -> 전처리 토큰으로 분리하는 단계
전처리 실행 단계
#include 파일 내용 복사 -> #define 코드 치환 -> #if, #ifndef 코드 치환 -> #pragma 등 컴파일러 명령문 해석
실행 문자 셋으로 변경
인접한 문자열 합치기
컴파일 단계 : 소스 파일들을 어셈블리어로 변환
해석 유닛 생성(Translation Unit)
전처리기 토큰을 컴파일 토큰으로 변환 -> 컴파일러가 컴파일 토큰을 해석해 해석 유닛 생성(해석 유닛을 각 소스 파일 별로 하나씩 존재하게 됨)
인스턴스 유닛 생성(Instantiation Unit)
- 컴파일러가 해석 유닛을 분석해 템플릿 인스턴스 확인 -> 템플릿들의 정의 위치가 확인되면 해당 템플릿들의 인스턴스 화가 진행 -> 이를 통해 인스턴스 유닛 생성
어셈블 단계 : 실제 기계어로 이루어진 목적 파일(obj)로 변환
링킹 단계 : 목적 파일들을 하나로 모아 실행 파일 생성(exe)
힙과 스택
메모리 구조
- 프로그램이 실행되기 위해서는 먼저 프로그램이 메모리에 로드(load)되어야 합니다.
또한, 프로그램에서 사용되는 변수들을 저장할 메모리도 필요합니다.
따라서 컴퓨터의 운영체제는 프로그램의 실행을 위해 다양한 메모리 공간을 제공하고 있습니다.
프로그램이 운영체제로부터 할당받는 대표적인 메모리 공간은 4가지 있습니다.
1. 코드(code) 영역
2. 데이터(data) 영역
3. 스택(stack) 영역
4. 힙(heap) 영역
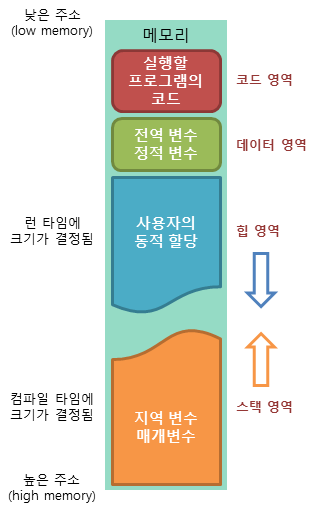
코드(code) 영역
메모리의 코드(code) 영역은 실행할 프로그램의 코드가 저장되는 영역으로 텍스트(code) 영역이라고도 부릅니다.
CPU는 코드 영역에 저장된 명령어를 하나씩 가져가서 처리하게 됩니다.
데이터(data) 영역
메모리의 데이터(data) 영역은 프로그램의 전역 변수와 정적(static) 변수가 저장되는 영역입니다.
데이터 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸합니다.
스택(stack) 영역
메모리의 스택(stack) 영역은 함수의 호출과 관계되는 지역 변수와 매개변수가 저장되는 영역입니다.
스택 영역은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸합니다.
이렇게 스택 영역에 저장되는 함수의 호출 정보를 스택 프레임(stack frame)이라고 합니다.
스택 영역은 푸시(push) 동작으로 데이터를 저장하고, 팝(pop) 동작으로 데이터를 인출합니다.
이러한 스택은 후입선출(LIFO, Last-In First-Out) 방식에 따라 동작하므로, 가장 늦게 저장된 데이터가 가장 먼저 인출됩니다.
스택 영역은 메모리의 높은 주소에서 낮은 주소의 방향으로 할당됩니다.
힙(heap) 영역
메모리의 힙(heap) 영역은 사용자가 직접 관리할 수 있는 ‘그리고 해야만 하는’ 메모리 영역입니다.
힙 영역은 사용자에 의해 메모리 공간이 동적으로 할당되고 해제됩니다.
힙 영역은 메모리의 낮은 주소에서 높은 주소의 방향으로 할당됩니다.
스택과 힙의 장단점
스택
매우 빠른 액세스
변수를 명시 적으로 할당 해제 할 필요가 없습니다.
공간은 CPU에 의해 효율적으로 관리되고 메모리는 단편화되지 않습니다.
지역 변수 만
스택 크기 제한 (OS에 따라 다름)
변수의 크기를 조정할 수 없습니다.
힙
변수는 전역 적으로 액세스 할 수 있습니다.
메모리 크기 제한 없음
(상대적으로) 느린 액세스
효율적인 공간 사용을 보장하지 못하면 메모리 블록이 할당 된 후 시간이 지남에 따라 메모리가 조각화되어 해제 될 수 있습니다. (C++ 에서는 직접 해제해 줘야함)
메모리를 관리해야합니다 (변수를 할당하고 해제하는 책임이 있습니다)
출처 : https://junghyun100.github.io/%ED%9E%99-%EC%8A%A4%ED%83%9D%EC%B0%A8%EC%9D%B4%EC%A0%90/
스택(Stack)과 힙(Heap) 차이점
해당 Post는 스택(Stack)과 힙(Heap) 차이점를 정리한 파일이다.
junghyun100.github.io
'프로그래밍 공부 > Unseen 3기 준비' 카테고리의 다른 글
| [UNSEEN 테스트 대비] 게임에서의 벡터, 행렬, 내적, 외적의 활용, 회전의 표현 (0) | 2025.01.11 |
|---|---|
| [UNSEEN 테스트 대비] A* 길찾기, FSM, 비헤이비어트리, Quadtree 공간 분할 (0) | 2025.01.08 |
| [UNSEEN 테스트 대비] Map, Unordered_map, list, vector, array 동작원리 (0) | 2025.01.05 |